Electronic ink (e-ink) displays are composed of an array of tiny micro-capsules embedded in a layer between two electrodes. Each micro-capsule in the array contains both positively charged white particles, and negatively charged black particles. These particles are suspended in a transparent oil. When a voltage is applied across the micro-capsule, the black and white particles separate. With either the black particles or white particles moving to the top of the micro-capsule, creating a white or black dot depending on the charge [1].
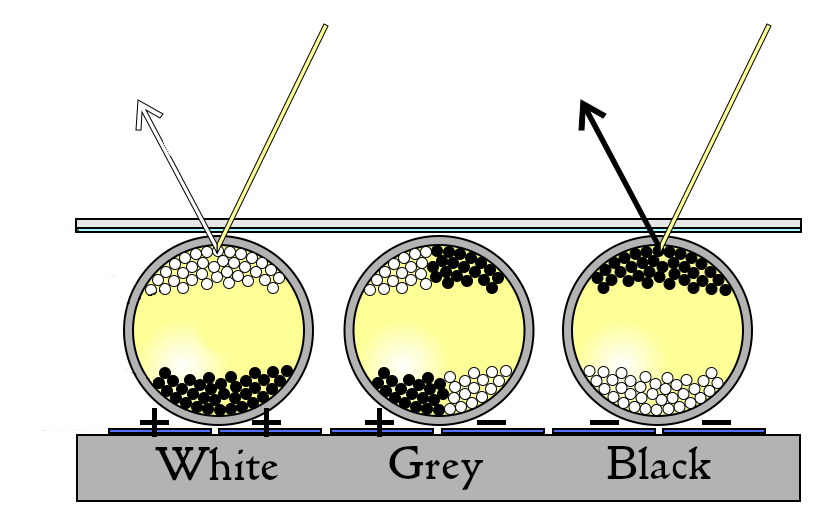
The array of micro-capsules together creates the appearance of text or images on the display, that is updated by changing the voltage over the electrodes. The particles in the micro-capsules remain in place even when the power is turned off, meaning that e-ink displays are able to hold their images even when not actively powered.
E-ink displays were developed by a company called the E Ink Corporation, founded in 1997 by a group of researchers from the Massachusetts Institute of Technology (MIT). The technology behind e-ink displays was based on a concept called "electrophoretic displays," which had been researched by several scientists in the 1970s and 1980s. E Ink's first commercial product was the "E Ink Vizplex", which was introduced in 2004 and used in the first generation of Amazon's Kindle e-reader [2]. Since the release of the Amazon Kindle in 2007 ebook readers have become increasingly prevalent. They confer many advantages for the reader:
Having recently switched from reading paper books to reading on an e-reader, it occurred to me that an additional advantage of reading on an electronic device is the data that is captured whilst reading. This project aims to make use of some of that data generated.
This project is named after Manjushri a bodhisattva in Mahayana Buddhism associated with wisdom and learning. He is often depicted holding a sword and a book, symbolising the cutting of ignorance and the attainment of knowledge. Manjushri is considered to be the embodiment of the wisdom of all buddhas, and is often invoked in tantric practices for the attainment of higher wisdom and understanding. He is also one of the most revered and important figures in Tibetan Buddhism [3].

Manjushri is an appropriate name for this project that aims to make better use of annotations made on a Kobo, to aid learning. The objective is to extract multi-word annotations created on the Kobo Clara HD outputting a file of quotations, and for single words a vocabulary list with definitions that can be learned through Anki [4].
The Github repository for the project is located here: manjushri_kobo. At a high level the project is structured as follows, where main is the entry point for the project.
.
├── core
│ ├── argparser.py
│ ├── database.py
│ ├── logs.py
│ ├── quotes.py
│ └── words.py
├── logs
│ └── manjushri_kobo_.log
├── main.py
├── README.md
├── requirements.txt
├── run_manjushri_kobo.sh
└── sql
├── books_read.sql
└── extract_annotations.sql
The argparser.py module allows for passing arguments from the command line for example the location of the kobo .sqlite database, which is connected via a context manager in database.py. Logging is setup in the logs.py module.
A SQL query is run against the kobo database to extract all highlights made, which are split based on a max_word_len parameter into "quotes" and "words". Quotes are then extracted to an org-file in quotes.py. Finally words are cleaned and definitions found in words.py before being written to .csv.
For this project I took the opportunity to try Python 3.11. This latest Python release includes significant performance increases being between 10-60% faster than Python 3.10 due to updates to CPython [5]. In addition to faster code execution, Python 3.11 brings:
The most immediately obvious and welcome change is in more refined and specific error tracebacks introduced in PEP 657 [7]. In the example below the traceback shows the exact expression causing the error, instead of just the line in previous versions.
Traceback (most recent call last):
File "distance.py", line 11, in <module>
print(manhattan_distance(p1, p2))
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "distance.py", line 6, in manhattan_distance
return abs(point_1.x - point_2.x) + abs(point_1.y - point_2.y)
^^^^^^^^^
AttributeError: 'NoneType' object has no attribute 'x'
Org-mode is an open-source, plain-text outlining and note-taking tool for the Emacs text editor. It is built on top of the org-mode file format, which is a simple, plain-text format for organising notes, lists, and other information [8]. Org-mode provides a wide range of features for managing and organising information, including:
In the core/quotes.py module I extract my annotations longer than 2 words to an org file called book-annotations.org. I particularly like this since org-mode provides a hierarchical approach making it easy to fold and unfold sections of the document.

For the task of looking up word definitions I tried using the Kobo proprietary Oxford Dictionary of English, but could not determine a way to query this through Python. So I then explored some python libraries for the task, namely:
I decided not to use these since many words could not be found, and I wanted to avoid the dependency of an external request. After some experimentation WordNet from the NLTK [9] library gave the most succinct and reliable definitions.
The NLTK is an open-source library for natural language processing (NLP) in Python. NLTK provides a wide range of tools and resources for working with human language data, including: tokenization, part-of-speech tagging, parsing, named entity recognition (NER), sentiment analysis, text classification, stemming, and lemmatization.
WordNet is a lexical database for the English language that is included with the NLTK in Python. The WordNet lexical database groups words into sets of synonyms (synsets) and provides a hierarchy of concepts (taxonomy) to organize the synsets[10]. The NLTK library provides several functions for interacting with the WordNet database, such as looking up synonyms, antonyms, and definitions of words.
In the core/words.py module I use NLTK to clean words by:
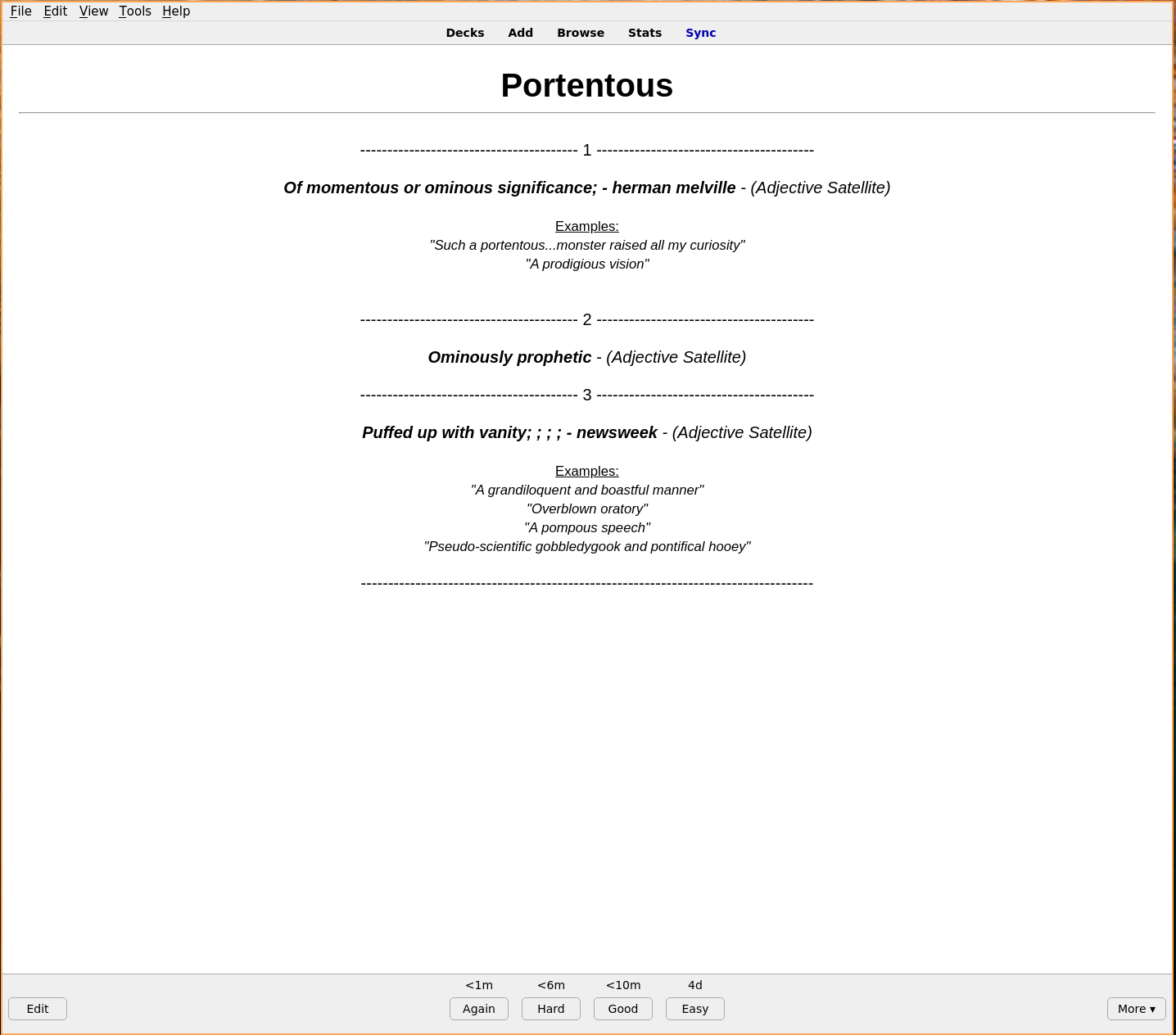
Then I use WordNet to lookup definitions, part of speech, and examples. These results are marked up with HTML tags and written to a csv file that can later be imported into Anki, for example a result in the csv file looks like this:
<h1>Portentous</h1>,"
--------------------<large> 1 </large>--------------------
<em><b>
Of momentous or ominous significance; - herman melville</b> - (Adjective Satellite)</em><small><u>
Examples:</u>
<em>""Such a portentous...monster raised all my curiosity""</em>
<em>""A prodigious vision""</em>
</small>
--------------------<large> 2 </large>--------------------
<em><b>
Ominously prophetic</b> - (Adjective Satellite)</em>
--------------------<large> 3 </large>--------------------
<em><b>
Puffed up with vanity; ; ; ; - newsweek</b> - (Adjective Satellite)</em><small><u>
Examples:</u>
<em>""A grandiloquent and boastful manner""</em>
<em>""Overblown oratory""</em>
<em>""A pompous speech""</em>
<em>""Pseudo-scientific gobbledygook and pontifical hooey""</em>
</small>
-------------------------------------------"
This csv file can be imported into the Anki flashcards program to have a tool for memorising new vocabulary.
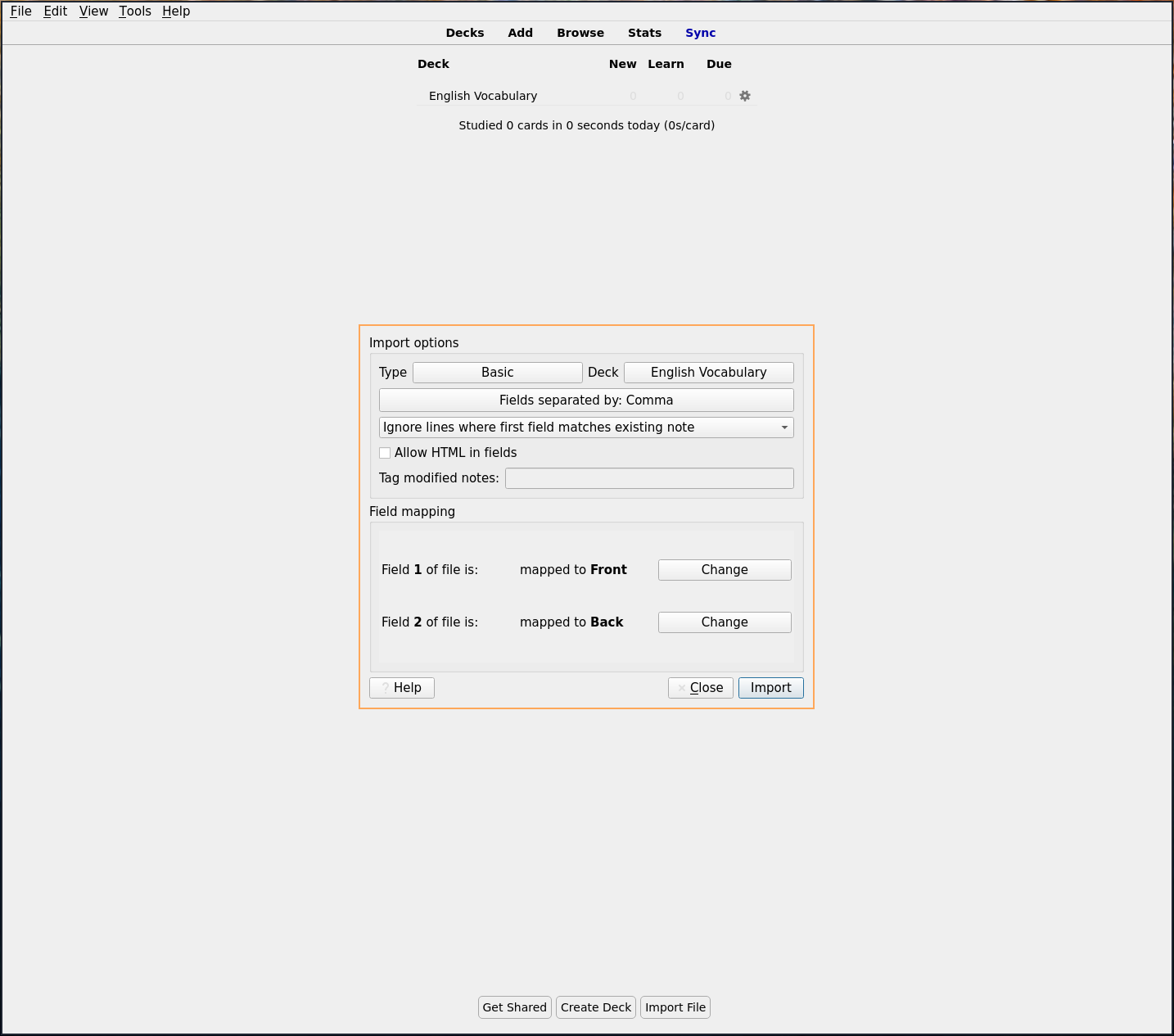
After importing the csv to an existing or newly created deck the words can be studied.
This short project I hope will be useful to get more value from reading on the Kobo, assisting in learning new vocabulary, and providing a reference library of quotes from books read. As e-ink displays slowly eat up the market I imagine more tools will become available for this, but I think using free and open source projects like Anki, and Org mode makes the outputs more generally useful.
In the future I might extend this project to include some reading statistics in the output logs. For example it would be interesting to log the books read, time spent reading broken down by month, fastest books read, words read per day, etcetera. The project could also be set to run directly when connected by setting a udev rule to launch the run_manjushri_kobo.sh bash script.

{kind=link}